Hyperlinks

Concept of Hyperlinks
Hyperlinks, often simply referred to as links, are references in digital documents that users can follow to access other documents or specific parts of a document.
They are a fundamental component of the World Wide Web, allowing for the interconnection of content across the vast expanse of the internet. Hyperlinks can be text-based or image-based and are typically distinguished from regular text by being underlined and/or colored, usually blue for unvisited links and purple for visited ones.
Hyperlinks can be text-based or image-based and are typically distinguished from regular text by being underlined and/or colored, usually blue for unvisited links and purple for visited ones.
Implementation for Web Developers
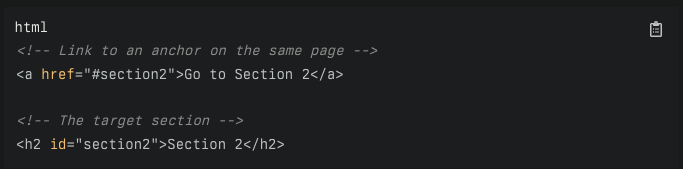
Web developers implement hyperlinks using HTML (Hypertext Markup Language), specifically the anchor tag <a>. The anchor tag includes an href attribute, which specifies the destination URL (Uniform Resource Locator) of the hyperlink. The content placed between the opening <a href="..."> and the closing </a> tags is what users interact with, such as text or images
How Browsers Handle Hyperlinks
When a user clicks on a hyperlink, the browser processes the href attribute's URL, generating an HTTP GET request to retrieve the resource from the specified web address. This request is sent to the server hosting the target resource, which then responds with the content of the requested page or file. The browser then renders this content for the user, effectively completing the navigation initiated by the hyperlink.
Browsers also provide visual cues to users, such as changing the cursor to a hand icon when hovering over a link, and typically display the URL in the status bar at the bottom of the window. These cues help users understand that the text or image is clickable and will take them to another location.
In summary, hyperlinks are a critical component of web navigation, allowing users to explore the vast expanse of the internet seamlessly. For web developers, understanding how to effectively use the <a> tag and its attributes is essential for creating intuitive and navigable websites. Meanwhile, browsers play a crucial role in processing these links, making the interconnectedness of the web possible.